
Over the course of the past 12 years, I’ve embarked on a journey to achieve top Test Coverage.
The end result is a process where I routinely discover and design 2× to 6× as many test cases compared to the previous average for software artifacts of similar size and complexity, and where such tests have objectively decreased the number of incoming customer defects for a such-tested feature.
Namely 50-90 test scenarios where the average was 10-30, and over 150 test scenarios where the average was around 50. But that is actually the smallest of the benefits.
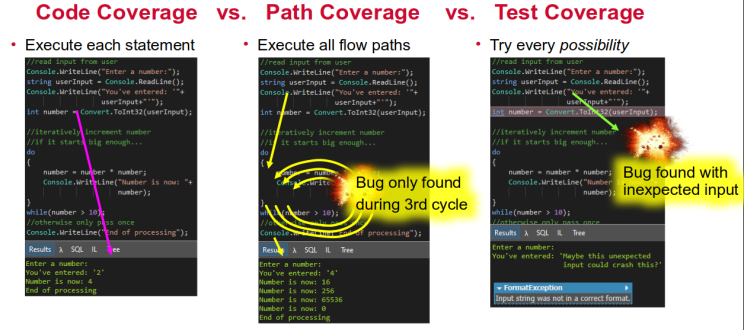
Test Case distribution: are you missing some areas completely?
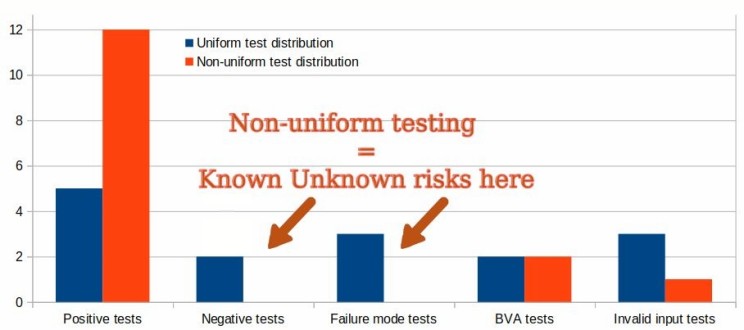
Very important is the test coverage distribution. Most informally designed test cases have non-uniform distribution: some areas of the software are covered extensively, while other areas are not covered at all (see Fig.2).
On the other hand, the test cases designed using the analytical techniques I found, teach and use are assured to always cover all known areas. Better yet, upon encountering unknown areas where some defects hide, they self-repair and fix this gap in the next iteration with “testing of tests” and QA Root Cause Analysis.
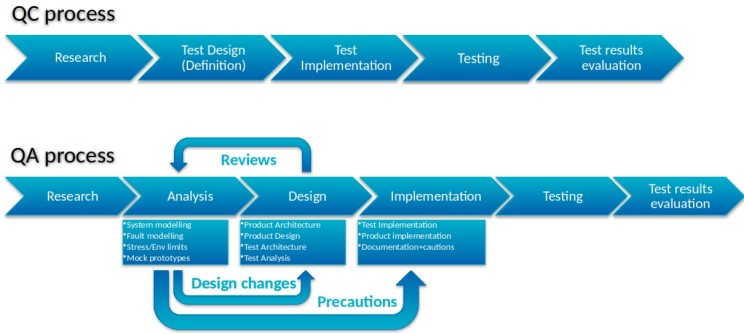
Feedback to developers is what separates QA from QC
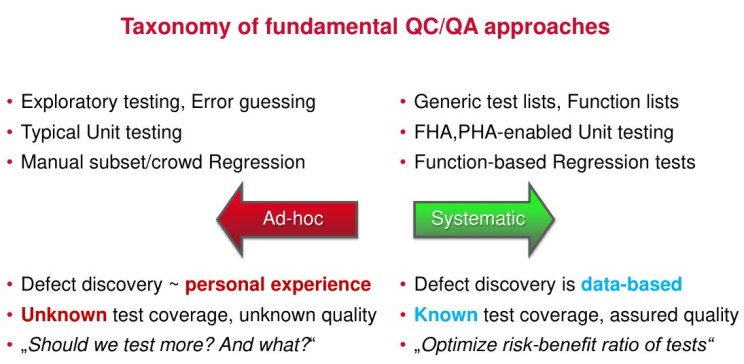
Even more important is Technical Risk Management and Developer Feedback. The difference between Quality Control and Quality Assurance is that QC is just testing to prevent defects from being released to customers after they were coded, period. While Quality Assurance goes long way to prevent defects and risks during software design, implementation and use (See Fig.3.)

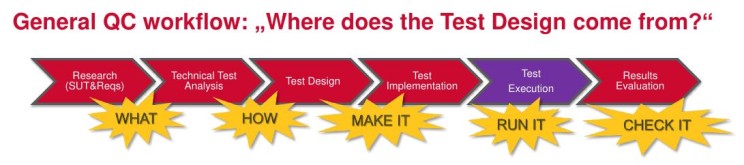
That requires some kind of design Reviews, where the QA analyses the emerging system for risks and reports them to Developers early on so that they could be mitigated by architecture or code checks (see Fig. 4 for flowchart.) And some kind of Failure Mode Criticality Analysis, which systematically finds out what could go wrong, how could it happen, what absolutely must not go wrong, and how to prevent that.
The QA process I discovered, adapted and follow is guaranteed to do that – the feedback I cherish the most is one senior developer’s admission that he didn’t believe in the process when he first saw it, but then he found out it really works and prevents defects before they’re coded.
Data-based Risk management instead of guessing in the dark
And lastly, you may be thinking that so many test cases are actually undesirable – who has time for such extensive testing nowadays, right? But even in such case, my QA techniques have significant benefit. If you use Technical Analysis to discover 100 test cases, it means that you have discovered 100 technical risks across all areas of the software. That empowers you to do an informed Risk-Based Testing, selecting only a subset of, say, 30 test cases covering just the biggest risks.
How does that compare to the average 30 test cases? The number seems to be the same, but see Figure 2 again. Without the technical test analysis, those 30 test cases are almost randomly selected and non-uniformly distributed. They cover some risks, even extensively… But completely ignore other risks. They do not solve the “known unknowns” issue. How can you know that the 30 test cases you have are the important ones, and nothing dangerous is lurking in the 70 you have never seen? What monsters are hiding in the dark?

Yet I am certainly not some “QA superman” who meditates in Zen and wakes up Enlightened with superb test coverage supernaturally materializing in my brain. Anyone else can achieve the same, only if they have the same tools. The tools which I have discovered, refined and shared with other through the course of my 12-years long journey.
Hacking and LEAN-izing the Aerospace QA tools
The tools which come from the State-of-the-Art Quality Assurance of the Aerospace Industry – NASA, RTCA, RAPITA, AdaCore and others. As used by NASA itself, Boeing (yes, including lessons learned from the 737MAX), Airbus, EADS, and other giants.
Yet for practical QA purposes of a non-regulated software development, these tools were far on the formal end of the scale. So I hacked them. I’ve cherry-picked them. I took the principles and biggest value, and threw away formalities, excessive documentation etc. In short – “LEAN-ized” them. From hundreds of pages to single sheet of A4 paper.

What are these tools? Quality Assurance Lists, Cheatlists and Checklists.
Step one: Function Lists
In Waterfall, software creators used to write Detailed Design Specifications and Functional Specifications. These perfectionist documents designed 100% of the software down to the last detail on hundreds of pages of paper – and as any plan, they usually didn’t survive the first contact with reality.
Yet software development just swapped one unhealthy extreme for another. Trial-and-error hacking of “prototypes” which had to be extensively refactored or rewritten everytime the developer encountered a surprise requirement, dependency or pre-requisite which wasn’t expected. That creates a lot of defects – a lot! -, is completely at odds with any stable design and architecture – and complicates work for the QAs.
Introduce the Function Lists (FnLists). Inspired by the aerospace’s Preliminary Hazard Analysis, FnLists are just a bullet-list. No details, just enumeration of functions.
Agile’s User Stories based on “Personas” are the official requirements, yet on their own, absolutely insufficient for real development. Something important is missing. Consider this example: “As an administrator, I want to add users so that they could…”
Explicit functions of the User Story… Versus Implicit/Secondary functions
Okay, that’s a requirement. “Function: Add users as administrator”. Let’s call it “Primary function” or “Explicit function”, because this is what the user/product owner asked for. But wait, that spawns many more requirements!
- If the users should be only added by an “administrator”, there need to be User groups. These have to be coded.
- Also, these groups need to have different privileges, at least “non-privileged users” versus “admin users”. Privileges system needs to be coded.
- When a user is created, we need to provide a password.
- If the user is created with a password, we may also need function to reset the password?
- If Story asks for adding the user, what about deleting the user, too?
These are what Function Lists call “Secondary functions” or “Implicit functions”. Noone defined them, noone thought about them, but they are inseperably tied to the Explicit functions. These are the “surprises” which cause the frequent refactoring, redesigns and defects… If the developers only figure them out by trial-and-error once they’re in the middle of writing the code.
But what if they could be identified before writing the code? Then the developers save themselves from a lot of refactoring, and the QAs prevent a lot of defects! All courtesy of Function Lists. They don’t try to design the software “on paper” to the last detail as the FSs and DDSs did. Instead, they are a mental excercise – the QA works with the Developer to imagine how the entire feature will be coded, to identify all “surprise” Secondary/Implicit functions up-frond.
Wait, it’s not all. These secondary functions are abstract in nature – they are more like requirements. But when it comes to coding them, there is a third layer – in FnList lingo, “Implementation functions”. Eg.
- For the user passwords, write function to securely encrypt the password using trusted library, and securely store it to password database
- And related – securely Connect to the secure password database
- For the user groups, securely handle group assignment
- For the privileges, securely elevate privileges of a submitted user to “Admin”
Etc.
The point is this: if the Developers starts writing these Implementation functions without considering their future re-use by Secondary Functions, they will inevitably hit a moment where they think: “Wait, this function could have served two other functions, not just one. But now I have to extensively rewrite it to allow that.” Again – refactoring, resources waste, possible defects.
So what is a Function List and how do you do it?
- You take every primary/explicit function from the User Stories and PO and enumerate it in a bullet list.
- For every explicit function in the first bullet list, you identify all the secondary/implicit functions up-front. All the dependencies, requirements, counterparts. Just as another bulletlist with short descriptions!
- For every primary and secondary function, identify all the Implementation functions which are known up-front to be required to make the Primary and Secondary functions work.
The result is one or two pages of A4 bullet lists:

Flexible. Adaptable. Still supporting agile development and frequent changes. Raising clarification questions to the customers/PO even before a prototype discovered something missing.
And incredible help to the QA. Because every item of the Function list becomes:
- A unit test – FnLists give us Data-driven Test-Driven Development!
- A complete suite of end-to-end tests (integrated system tests) of all Basic Positive functionality which should be tested
- Provided the code is testable and reachable from the outside, writing these tests ought provide 100% Code Coverage
- All this while significantly reducing the need for refactoring and redesigns of a half-baked code
So many benefits for so little effort! And all it takes is three to seven days of QA/Developer interactions, working on the Function List together in the QA Feedback loops.
Step two: Failure Mode Effect Criticality Analysis (optional)
The “serious” engineering fields, like construction, automotive or aerospace, know a technique called FME(C)A. It’s a table where you list all the components of the system. Then for each component, you add rows for all the ways in which the component could fail. And you determine how big a problem would it be, should that failure happen to a customer:

The obvious issue is: how do you populate the rows of the FMECA table, if you don’t want to do White-Box testing (you shouldn’t) and list internals of the code?
Function Lists bring obvious solution. Each bullet item of the Function List bullet lists becomes a FMECA table entry. Now it’s easy as pie to list the Failure Modes, Effects and Severity/Criticality on the functional level!
If the FMECA detects a possible (and probable) failure with unacceptably high severity? Then the QA provides feedback-suggestion to alter the design and introduce some mitigations in the code, so that the discovered risk of critical failure can be either circumvented entirely, or mitigated.
FMECA is optional, only done where it makes sense. It probably doesn’t make sense to run FMECA eg. for animations… But when it comes to encrypting user data and Compliance with GDPR? Then FMECA can easily have the value of it’s weight in gold.
Step 3: Test Classes Cheat Sheet/Checklist
For years, I’ve been tackling the issue of non-uniform test distribution.
For years, I’ve been searching for a solution which would somehow guarantee that no important area of testing is missed of forgotten.
I found that solution, and much more to it, in Test Classes.
Originally, Test Classes were a sidenote in the bureocratic standard IEE829 for test planning. Noone does test planning anymore, but let’s not spill the bathtub with the baby – could there be something valuable, that could be scanvenged? Oh my. Yes! This technique alone increased our test coverage to 200% !
Test Classes were simply an enumeration of categories of tests. But if you hack them, you could take that concept to create a definitive enumeration checklist/cheat-sheet of all the types of tests and areas of testing that need to be tested on your product/feature, so that nothing is forgotten and everything is covered!
I quickly put together a product-agnostic basic Test Classes Cheat Sheet (now in it’s third version):

How does it work?
First, take your Function List, iterate through all of the Primary and Secondary functions and convert them to test cases. That is your basic positive testing and basic negative testing (test classes A.2, B.1 and B.2). That should give you 100% Code Coverage.
But any real testing needs to go beyond that – testing invalid user inputs, values beyond allowed Boundary Values, unexpected environmental events like DST rotation (when “time goes backwards”, it wreaks havoc on software logs and collation) and others. (See Fig. 1 again.)
So after you’re done with you neccessary, but insufficient Basic Positive Testing? Simply iterate through the Test Classes Cheat Sheet and design more test cases for each applicable category (meaning test class). And if you think some category doesn’t apply – that’s all right, but you have to write down a reason why you believed so.
Only keep in mind that it’s not the point to write manual test cases. The point of Function List and Test Classes Cheat Sheet is not to “plan” anything, nor to do anythign manually. It is technical risk discovery and management – to find the risks in the software being created, and cover them with test cases so well that these risks are negated, managed or controlled.
When you have the list of test case designs = risks to be tested, you implement those test cases. This has always happened, because if you use Systems Thinking to decompose how do you test, it always has separate phases of test design (=think what and how to test), implementation (=specify the detailed steps and parameters to achieve that design), testing (=executing the implemented designs) and verification (figuring out the results, whether the test has passed or failed):
Only in the implementation phase, you can automate. Only after you have implemented the test designs as automated scripts can you automatically run them.
So when working with TCCS, restrict yourself to so-called High-level test cases – short summary of what is being tested, what for, only very briefly how. You may or may not even include the Expected Results in this phase. The detailed Low Level Test Cases can be created on the basis of the TCCS list as automated scripts.
This isn’t Waterfall reimagined – this is the most extreme Shift-Left Testing possible
The techniques described herein have nothing to do with “Waterfall” or “planning”. On the contrary – they are extreme “Shift-left testing”. You just cannot mistake technical analysis for bureocratical planning.
The Function List means that the QA effectively tests the design of the feature before the first line of code is written. Before even the unit tests are defined. And then, the Function List turns itself to be a superb source of Unit tests, which are the official definition of Test-Driven Development. That is the furthest Shift-Left Testing possible!
The FMECA means that QA effectively tests the design of the feature for critical errors and vulnerabilities again before the first working prototype of code is ever delivered for testing.
Even the Test-Classes based High-level test designs are 100% parallel to development. It’s not the next step as in Waterfall, it happens while the Developer starts coding. So enough of the “Waterfall” nonsense already! This kind of insults is brought as a weapon by people who prefer informal, ad-hoc hacking and testing. But that has nothing to do with either Waterfall, Agile or Shift-left. It’s entirely different chart.
Superb test coverage takes time. Who is willing to invest it?
In the end, when the excuses, false analogies and sales pitches are off the table, this all boils down to single question.
Do you really want quality? And how much time are you willing to invest to get that quality?
I can give you some exact numbers.
- The Function List feedback and gathering with a Developer takes about a work week.
- FME(C)A, if done, also takes about a work week.
- Covering all bases with Test-Class driven cheatsheets/checklists and creating the test cases to reach the maximal coverage takes from two weeks for mid-size features, up to four weeks for very large, high-risk to users, or complex features.
And the honest answer is – that most software companies don’t want quality. Not really.
What they really want instead is to deliver something somewhat little tested within the mandatory Two Weeks Cycles, prescribed by the corporate “Anti-agile Agile”:

What an irony! I’ve spent 12 years maximizing my skills in test coverage and QA analytics, design, architecture and feedback, only to be told these are not in market demand. Ideally two-weeks long, quick testing without any system analysis or critical design review is. But once I saw how well it works, once I experienced the system in it, once I saw the results – I cannot go back. So where does that leave me?
I’m up for grabs for any team of my company, or any other company, which sees the value in the maximal-test-coverage way of QA with Function Lists, optional FMECA and Test-classes based design/creation of test cases that I do. Anyone who would actually want and appreciate me doing that for them, and not consider it a liability. Anyone who would be happy to grant the time and resources needed, knowing that the result is worth it.
And if you’d just like to try-out or demo these techniques and tools in your company and need to learn more, ping me – I can arrange a free, open-source, open-domain training webinar for your software QAs. I’ve been teaching this as I progressed both internally and externally, even to university students.
Leave a Reply
You must be logged in to post a comment.