
(Part 1 of 2-part IBM z/OS crash course “From Linux to Mainframe in one day”)
While mainframes can work interactively, “online”, this is mostly reserved for special applications like the IBM CICS transaction server. Most of the workload runs in so-called “batch processing” mode – running scripts., kind of similar to Cron+Bash combo on Linux.
These scripts are written in a mainframe-specific scripting language called JCL – Job Control Language. So as you can guess, the batch scripts are called “Jobs” in the mainframe lingo.
Learning JCL is the same case as everything mainframe – exponential. To take off and do some real work, you need to learn just about 10 basic keywords. But when you want to dig deeper into recursive procedures and whatnot, it’s hours of studying the MVS JCL Reference manual (as with everything Mainframe, grab a copy in PDF and store it on your PC so that you can access it with few clicks.)
But this being a Day 1 tutorial, let’s go trough these basics.
JCL language structure
How to read the grammar? My understanding of JCL has leaped light years when I coded JCL tokenizer (the part of parser which does the actual parsing but without acting on it).
The key point to memorize is: JCL syntax is whitespace-driven. (When I say whitespace, I mean only space – the mainframes don’t work in LUW-native ASCII, but different encoding called EBCDIC, which considers all whitespace within the ASCII table except regular space and CR/LF to be invalid characters.)
JCL grammars is:
- positional, with tokens of the language separated by whitespace (this is how the JCL parser works – splitting the scripts by whitespace and relative positions)
- atomic – the JCL batch job consists of separate Steps, where each Step executes some unit of work and depending on whether it works or fails, subsequent steps may or may not be executed
- hierarchic – some lower-level keywords are tied to the higher-level keywords above them
JCL grammar
Every line begins either with
- the “//” statement to denote valid line,
- “/*” to comment-out the entire line,
- blank character in the 1st column in case of in-stream datasets, a.k.a. inline files contents
- optional “*/” (or different custom-specified) delimiter to properly terminate the in-stream dataset
Then, without whitespace, comes the label – name of the job, name of the step, label-name of the dataset you want to pass to some program etc. This is optional, but if you skip it, guess what – you must replace it with whitespace, because JCL is whitespace-separated positional.
Then, after whitespace, comes the reserved control keyword.
Then, after another whitespace, comes the coma-separated list of parameters of that keyword.
All-in-all, these are valid syntaxes:
//label keyword param=value,param2=value2
//labelx keyword param=value in#line#comment
// keyword param1=’looooooooooooong value’,
// param2=’new value2 on newline after terminating coma’
The key JCL keywords
JOB needs to be the 1st statement in a JCL for it to be valid.
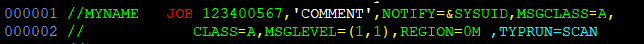
Just after the JOB statement, separated by comas, come required parameters.
The number right behind JOB is “accounting information”, which is assigned to you personally and long, long ago, truly served for grabbing money for your CPU workload from your division of the company. If you specify incorrect accounting number, the Security system will kill your job before it ever runs, and clear it from the queue like it never existed. Keep this in mind when modifying other people’s JCLs!
NOTIFY is optional and says that some username will be interactively notified of how the job run or failed. &SYSUID is system variable, which is always your username.
MSGCLASS determines how much extra output/logging you will get from the system, where it will be displayed, and how soon will it disappear. CLASS determines where your job will run, and since each CLASSes has it’s purpose set by the IT department, you better learn which CLASS are you allowed to use and not misbehave.
REGION can set a memory (like RAM) limit on the entire job – you can also specify it at individual step level.
And optional TYPRUN=SCAN will not execute the job, but analyze it for syntax errors just like a compiler on a LUW system. Notice how it’s blue – that’s because it’s separated by space, and hence considered a comment, not a part of the JOB command. If you remove that space, it will become valid and used.
JOBLIB is like a #include in a C program. It tells your JCL where from to run the external programs or scripts, so that you don’t have to provide that path (dsname) in each step separately.
Notice that JOBLIB is actually not a keyword – as you can see from the syntax highlighting, the keyword is DD, which we will address soon! The JOBLIB is a reserved label with special use.
Also notice that I am referencing two datasets here, not just one. That is called “DD concatenation” and means that both of them will be searched, in the exact order in which they’re specified.
SET declares and initializes a JCL variable. That variable can be then used using the &varname reference – just like you would use $varname on Linux, or %VARNAME% on Windows.

You can optionally give it label for readability, but it’s optional.
EXEC is a higher-level keyword to launch a program, external script or JCL procedure. It is followed by PGM=program executable filename, or PROC=procedure executable name. If you omit this specification, JCL procedure is assumed.
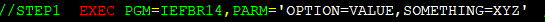
The program IEFBR14 shown here is a dummy program which does nothing on it’s own (it contains a single mainframe Assembler instruction Branch to Register 14″, where branching to r14 means “terminate a program”. Hence the name – plus IBM programs tend to start by “IE” prefix as a convention.
The PARM statement can be used to pass options or parameters to the program – just like the dash parameters in Linux. But the actual name isn’t fixed – it’s whatever the program programmer choses to read for input parms! Calling it “PARM” is just a convention, again.
But wait. Even if the program itself does nothing, like the IEFBR14, something can happen. That’s because to each EXEC statement, related DD statements can be tied. And these can allocate or delete files on their own!
DD is a lower-level keyword, which specifies datasets-labels combinations used by the EXEC to map dataset names to internal file labels in the programs/scripts. Of all the JCL keyword, DD is the most complex to handle.
First, some theory is needed to understand.
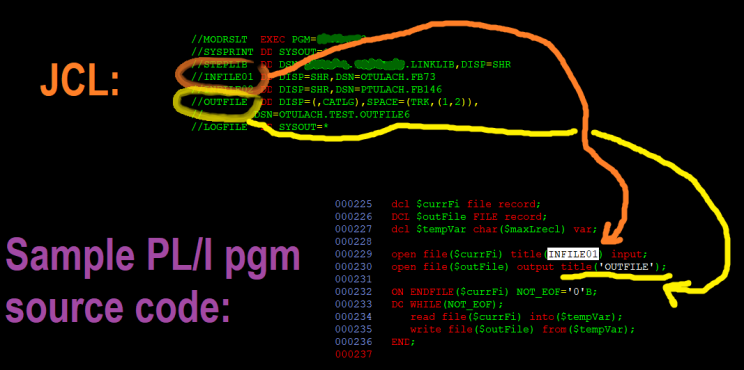
DD mapping of label (title) and path (dataset name)
See, unlike when you define paths inside a Linux C program, on mainframes, you don’t work with paths in your source code. Instead:
- the program uses up to 8-character labels, or titles, in it’s source code.
- The compiled program is then called by JCL, using the EXEC PGM= statement.
- Underneath that EXEC statement are DD statements…
- And each DD statement links the 8-character (expected by the program) on the left side of the DD statement, with the actual path to the file (dataset name) on the right side of the DD statement.
Confusing, I know, so let me show you an example:
Next super-important feature of DD is that besides linking the program labels/titles to actual DSN paths, it can actually manipulate files through it’s parameters.
JCL parameters to autonomously create and delete files
Depending on which DD DISP parameter you code, it can:
- create files using the DISP parameter: DISP=(NEW,CATLG) creates a new dataset if the program succeeds;
- delete existing dataset: DISP=(OLD, DELETE) deletes a dataset which was already existing if the program succeeds
- when creating new dataset, specify it’s size using the SPACE= parameter
- when creating new dataset, specify it’s record length (max line length) using the LRECL= parameter
Thus even if you run a dummy program IEFBR14, which does nothing, but then specify a DD DSN=something,DISP=(OLD,DELETE) – such program call will delete that dataset.
Special output file: JCL’s equivalent of Linuxe’s STDOUT
There is more. For output files, you don’t have to specify a real file on the disk. Instead, you can specify the output screen – exactly like STDOUT and STDERR are on Linux, Mainframe has SYSOUT= and name of the output files queue. The standard syntax to allow printing to terminal is:
//SYSPRINT DD SYSOUT=*
SYSPRINT is a convention used by most programs, see above. DD is the keyword, and SYSOUT means it will redirect output to the console log.
In-stream datasets: a file within the source
It is often useful to hardcode some data within a JCL script itself and then parametrize using variables – thus avoiding a need to run some external search&replace program. (Btw, it is called SuperC if you ever need it.)
This is a real syntax example:
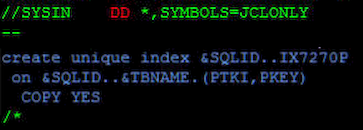
Notice few things:
- the syntax higlighting turns purple for in-stream dataset
- you should use a terminating sequence (normally “/*” but you can specify a special one using the ,DLM= parameter), but the system will handle it if you don’t
- the “&” are variables being dynamically searched-and-replaced in the instream DDs. But to enable this functionality, you need to code extra JCL keyword EXPORT=(*) before your SET statements, and you need to code the ,SYMBOLS=JCLONLY as a parameter of your instream DD’s DD statement
Summary
Writing a basic, valid JCL script is simple:
- first, code a line with JOB keyword and valid accounting nr. for your user account
- then you can, but don’t have to, code a optional line with DD keyword with reserved label JOBLIB to streamline your work.
- then you code a line with an EXEC keyword to call some useful payload – external program, another JCL, or another and more powerful script like IBM REXX
- then you code more lines with DD keywords tied to that EXEC statement. For any program which prints any kind of output on-screen, SYSPRINT is usually mandatory and without it, you will get a runtime error.
Leave a Reply
You must be logged in to post a comment.